
Kernel Servers using Rump
- Introduction
- Unix: A Distributed OS
- Client-Kernel Communication
- System Call Hijacking
- Performance
- Conclusions
Introduction
Foreword: this article is related to the rump project. For purposes of following this article it is enough to know that the rump project turned the standard NetBSD kernel into a highly componentized architecture and enabled running kernel components in userspace processes. For example, on an out-of-the-box installation it is possible to run an arbitrary number of unmodified NetBSD kernel TCP/IP stack instances in userspace.
Originally, the rump kernel and any application using the
kernel were limited to the same process. This was enough
for some purposes such as mounting and accessing file
systems. However, it made other operations awkward. For
example, configuring networking is usually done via at
least two separate commands: ifconfig and
route. In case the kernel is in the same
process as the application, kernel state is lost when the
application exits. Since base system utilities are written
with the assumption that they can exit while the kernel
retains state, they were not directly applicable to rump
in the original model.
In early 2009 I wrote the original version of rump sysproxy. It allowed clients to make system calls over sockets thereby allowing clients to reside in different processes from the rump kernel. This made the rump kernel retain state even if an application using the kernel exited. While the experiment showed that the basic concept worked, the original implementation was not very robust and could support only one client at a time. Since the implementation was not usable in the real world, the potential of sysproxy went largely unused for a long time.
This document describes a recent rewrite of the rump sysproxy functionality. The new implementation supports multiple clients, multithreading clients, violent client disconnects, and a number of other features such as client fork and exec. Persistent client reconnects are also supported, and this allows certain applications to nearly seamlessly recover from a kernel server crash or restart. Finally, rumphijack enables unmodified binaries to act as rump kernel clients and use for example file system and networking services provided by a rump kernel.
Figure 1. rump sysproxy architecture. Depicted are two hosts running one rump kernel each. The clients talk to the host kernel and a rump kernel. Each rump kernel can use a different component configuration, and although it is not depicted, each host can run an arbitrary number of rump kernels.
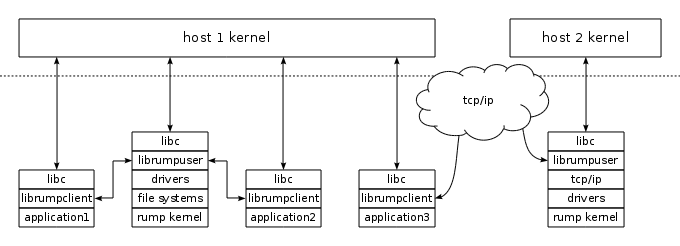
As a concrete example of functionality offered, let us examine the case of starting two TCP/IP stack servers and starting one Firefox profile for each one. IP configuration is equivalent to the normal case and omitted for presentation reasons. The browsers will be running on the same OS, but will be using two different TCP/IP stacks with different IP addresses, different routing tables and a different set of TCP/UDP ports. This allows for example easy separation of applications into different networks for privacy and other reasons, per-application TCP/IP stack modifications (even at a code level), TCP/IP stack crash recovery without total application failure and easy debugging of kernel code. However, in contrast to heavyweight full-OS virtualization solutions aiming to do the same, starting a per-application virtual kernel server is fast and straightforward.
golem> rump_server -lrumpnet -lrumpnet_net -lrumpnet_netinet -lrumpnet_virtif unix://netserv1 golem> rump_server -lrumpnet -lrumpnet_net -lrumpnet_netinet -lrumpnet_virtif unix://netserv2 golem> export LD_PRELOAD=/usr/lib/librumphijack.so golem> env RUMP_SERVER=unix://netserv1 firefox -P net1 -no-remote & golem> env RUMP_SERVER=unix://netserv2 firefox -P net2 -no-remote &
The rest of this article is structured as follows. First, we will look at how the structure of a Unix OS is inherently distributed and allows rump sysproxy to work without requiring any structural kernel modifications. In the next step, we will look at the client-server communication protocol. Then, we will investigate how running unmodified binaries against rump kernel services works, including what happens during fork and exec. Next, we discuss performance, and end with conclusions.
There is also a tutorial giving some ideas and instructions on how to use the functionality on a practical level. It can also be read independent of this article. All functionality described in this document is available in NetBSD-current as source and binary starting ca. March 2011 and will be available in the standard installation of NetBSD 6.0.
Unix: A Distributed OS
On a fundamental level, a Unix operating system works like
a distributed system: the kernel and user processes live in
different address spaces and information is explicitly moved
across this boundary by the kernel. This simplifies the
kernel, since data handled by the kernel can always be assumed
to be paged in and non-changing. A key point for the
article is that for every kernel request (syscall) there exists a
function call API (e.g. open(const char *path, int
flags, mode_t mode)) which abstracts the details of
what happens in user-kernel transport.
To get a better idea of how this works during system call
handling, let us examine the transactions that take place
when a process opens the file /dev/null.
-
The user process calls
open("/dev/null", O_RDWR);. - The libc system call stub sets up the arguments according to the platform's syscall calling convention and executes the system call trap causing a context switch to the kernel. The calling userspace thread is suspended until the system call returns.
-
The kernel examines the arguments and determines which
system call the request was for. The kernel begins to
execute
sys_open(). -
The pathname buffer is required in the kernel.
The
copyinstr()routine is used to copy the pathname from userspace to a buffer in kernelspace. -
The file system code does a lookup for the pathname,
and if found, the kernel allocates a file descriptor
for the current process and sets it to reference
a file system node describing
/dev/null. - The system call returns the fd (or error along with errno) to the user process and the user process continues execution.
This principle of the user/kernel interface being based on a distributed model is enough to support rump clients and servers without any modifications to the ABI. The client and the kernel do not even have to reside on the same physical host machine. Next, we will look at how we apply this principle to rump sysproxy.
Client-Kernel Communication
Before the client is able to communicate with the server, the client must know where the server is located. In the traditional Unix model this is simple, since there is one unambiguous kernel ("host kernel") which is the same for every process. However, in the rump model, the client can communicate with any rump kernel which may or may not reside on the same machine.
The listening address for the rump kernel is
specified using an URL.
Any client wishing to connect to that kernel instance should
specify the same URL as the kernel address. The connection
is established using host sockets. For example, the URL
tcp://1.2.3.4:4321/ specifies a TCP
connection on IP address 1.2.3.4 port 4321.
Currently, two protocol families can be used for client-server communication: Unix domain sockets and TCP. The advantages of Unix domain sockets are that the available namespace is virtually unlimited and it is easy to bind a private server in a local directory without fear of a resource conflict. Also, it is possible to use host credentials (via chmod) to control who has access to the server. The TCP method does not have these advantages — it is not possible to guarantee that a predefined port is not in use on any given system — but it does work over the Internet.
Of processes and inheritance
A process is a resource container with which state such as open file descriptors, permissions, and the current working directory is associated. In the original model where the client and the kernel share an address space, rump provides a set of interfaces for controlling the current process and thread. The caller can freely select the thread/process context which is used for kernel requests — since the client has access to the kernel address space, there are no limitations which we can impose. However, this is no longer the case with the client in a different address space.
The process context for a remote client is controlled by the rump kernel server. Whenever a client connects to a rump kernel and performs a handshake, a new process context is created in the rump kernel. All requests executed through the same connection are executed on the same rump kernel process context. Since the kernel enforces that a process can only access resources the process credentials allow it to access, remote clients will have access only to the resources the kernel grants them. This is exactly what happens in a "real" operating system environment and provides a building block for a security model on top of rump clients.
A client's initial connection to a rump kernel is like a login: the client is given a clean rump kernel process context with the correct credentials. After the initial connection, the client builds its own process family tree. When a client performs a fork after the initial connection, the child must inherit both the properties of the host process and the rump kernel process to ensure correct operation. Meanwhile, if another client, perhaps from another physical machine, connects to the rump kernel server, it gets its own pristine login process and starts building its own process family tree through forks. Due to a number of details involved in forks and execs, it is further described later in the document.
When a connection is severed, the rump kernel treats the rump kernel process as killed. It wakes up any and all threads associated with the connection currently blocking inside the rump kernel, waits for them to exit, and then proceeds to free all resources associated with the process.
Communication protocol
The communication protocol between the client and server is a straightforward mapping of what happens in usual process-server communication. For people familiar with the Plan9 project, this protocol can be viewed as the 9P-equivalent for NetBSD (and Unix in general), and shows that it is possible to create a reasonably similar architecture without having to start from a clean slate. It needs to be noted, though, that a protocol is just a means to an end, and it is the ability to create distributed virtualized kernel services that makes rump unique.
The request types for the protocol are presented in Table 1 and Table 2.
Table 1. Requests from the client to the kernel
| Request | Arguments | Response | Description |
|---|---|---|---|
| handshake | type (guest, authenticated or exec), name of client program | success/fail | Establish or update a process context in the rump kernel. |
| syscall | syscall number, syscall args (as in
syscallargs.h) |
return value, errno | Execute a system call. |
| prefork | none | authentication cookie | Establish a fork authentication cookie. |
Table 2. Requests from the kernel to the client
| Request | Arguments | Response | Description |
|---|---|---|---|
| copyin & copyinstr | client address space pointer, length | data | The client sends data from its address space to the kernel. The "str" variant copies up to the length of a null-terminated string, i.e. length only determines the maximum. The actual length is implicitly specified by the response frame length. |
| copyout & copyoutstr | address, data, data length | none (kernel does not expect a response) | Requests the client to copy the attached data to the given address in the client's address space. |
| anonmmap | mmap size | address anon memory was mapped at | Requests the client to mmap a window of anonymous memory. This is mainly for proplib, which allocates userspace memory from the kernel before performing a copyout. |
| raise | signal number | none (kernel does not expect a response) | Deliver a host signal to the client process. This is used to implement the rump "raise" signal model. |
Now that we know how things work, let us reexamine the
example of opening /dev/null. This
time we will compare the operations executed in the
regular case and in the rump case side-by-side. We
assume that the processes already exist and are capable
of executing system calls.
Table 3. Host and rump kernel syscall code path comparison
| regular kernel | rump kernel |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
System Call Hijacking
The only difference in calling convention between a rump client syscall function and the corresponding host
syscall function in libc is the rump_sys-prefix
for a rump syscall. This makes it possible to select the entity
the service is requested from simply by adding or removing a
prefix from the system call name. In some cases
it is easy and convenient to manually select the desired kernel.
For example,
when writing tests
such as ones testing a file system driver, all system calls
which are to be directed to the driver under test should go to
the rump kernel while others should go to the host kernel. The benefit
of explicit source-level selection is that there is full
control of which system call goes where. The downside is
that it requires source level control and compilation.
If we wish to use unmodified binaries, we must come up with
a policy which determines which kernel each system call
should go to.
One way to avoid the application having to choose which kernel
to call is to hide all the servers behind the host kernel in
a microkernel style with the help of subsystems such as
puffs
and pud.
For some functionality this works very well, the prime example being
file
systems. However, there are several downsides to
this approach. First, doing so requires host kernel support.
Second, starting and accessing the server may require elevated
privileges from an application, such as the right to mount
a file system or create a device node. Finally, it generally
just pushes the server choosing problem to another level:
for any given pathname it is easy to see which service should
be consulted to serve the request, but the system call where
an application opens a PF_INET socket
already lacks sufficient information to decide which server
should handle the request. In a microkernel operating system
this is fine, since there is, generally speaking, only one networking
server. In contrast, there can be an arbitrary number of
rump networking kernels in addition to the host kernel.
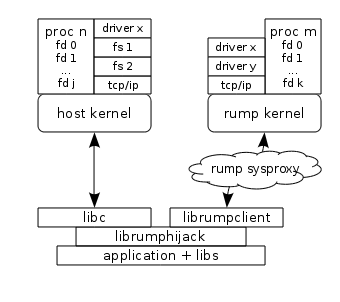
The rumphijack library provides a
mechanism and a configurable policy for unmodified applications
to capture and redirect part of their system calls to a rump
kernel instead of the host kernel. Rumphijack is based
on the technique of using LD_PRELOAD to instruct the
dynamic linker
to load a library so that all unresolved symbols are primarily
resolved from that library. The library provides its own
system call stubs that select which kernel the call should
go to. While the level of granularity is not per-call like
in the explicit source control method, using the classification
technique we present below, this approach works
in practice for all applications. The advantage over
the microkernel style global policy of system call routing is that the
application is still free to choose which kernel it wants to
request services from. Also, the approach does not require
any elevated privileges on the host even for operations such
as mounting file systems.
From the perspective of librumphijack, system calls can be divided into roughly the following categories. These categories determine where each individual system call is routed to.
-
purely host kernel calls:
These system calls are served only by the host kernel
and never the rump kernel, but nevertheless require
action on behalf of the rump kernel context. Examples include
fork()andexecve(). -
create an
object: the system call creates a file descriptor.
Examples include
open()andaccept(). - decide the kernel based on an object identifier: the system call is directed either to the host kernel or rump kernel based on a file descriptor value or pathname.
-
globally
pre-directed to one kernel: the selection of
kernel is based on user configuration rather than parameter
examination. For example, calls to
socket()with the same parameters will always be directed to a predefined kernel, since there is no per-call information available. In contrast, pathname-based calls can make the selection based on the pathname. Ultimately, the difference between the two is subtle, but it does exist. -
require both kernels
to be called simultaneously: the asynchronous
I/O calls (
select(),poll()and variants) pass in a list of descriptors which may contain file descriptors from both kernels.
Note: the categories are not mutually exclusive. For example,
socket() and open()
belong to several of them. In case open is given a filename
under the rump path prefix (e.g. /rump/dev/null),
it will decide to call the rump kernel to handle the request
and new rump kernel file descriptor will be returned to the
application as a result.
The rest of this section describes advanced rumphijack features beyond simple system call routing. Nevertheless, those features are commonly required for supporting many real-world applications.
File Descriptor Games
A rump kernel and host kernel file descriptor are differentiated by the numerical value of the file descriptor. Before a rump kernel descriptor is returned to the application, it is offset by a per-process configurable constant. Generally speaking, if the file descriptor parameter for a system call is greater than the offset, it belongs to the rump kernel and the system call should be directed to the rump kernel.
The default offset was selected to be half of
select()'s FD_SETSIZE
and is 128. This allows almost all applications to work,
including historic ones that use select()
and modern ones that use a fairly large number of file
descriptors. In case the host returns a file descriptor
which is equal to or greater than the process's hijack fd
offset, rumphijack closes the fd and sets errno to
ENFILE.
A problem arises from the dup2()
interface which does not fit the above model: in dup2 the new file
descriptor number is decided by the caller. For example, a common
scheme used e.g. by certain web servers is accepting a
connection on a socket, forking a handler, and dup2'ing
the accepted socket connection to stdin/stdout. The new
file descriptor must belong to the same kernel as the old
descriptor, but in case of stdin/stdout, the new file
descriptor numbers always signify the host kernel. To
solve this, we maintain a file descriptor aliasing table
which keeps track of cross-kernel dup2's. There are a
number of details involved, such as making sure that closing
the original fd does not close the dup2'd fd in the different
kernel namespace, and making sure we do not return a host
descriptor with a value duplicate to one in the dup2 space.
In fact, a large portion of the code in the hijack library
exists solely to deal with complexities related to dup2. The
good news is that all the complexity is fully contained
within the library and users do not have to worry about it.
Another issue we must address is protecting the file descriptors
used by rumpclient. Currently they include the communication
socket file descriptor and the kqueue descriptor which
rumpclient uses for I/O multiplexing. Recall, the socket connection
between the client and the kernel associates the client
with a rump kernel process context, and if the connection
is lost all process state such as file descriptors are lost with
it. In some scenarios applications typically want to close file
descriptors en masse. One example of such a scenario is
when an application prepares to call exec().
There are two approaches to mass closing: either calling
close() in a loop up to an abitrary
descriptor number or calling closefrom()
(which essentially calls fcntl(F_DUPFD)).
Since the application never sees the rumpclient
file descriptors and hence should not be interested in
closing them, we take precautions to prevent it from
happening. The hijack library notifies rumpclient every
time a descriptor is going to be closed. There are two
distinct cases:
-
A call closes an individual host descriptor. In addition
to the obvious
close()call,dup2()also belongs into this category. Here we inform rumpclient of a descriptor being closed and in case it is a rumpclient descriptor, it is dup'd to another value, after which the hijack library can proceed to invalidate the file descriptor by calling close or dup2. -
The
closefrom()routine closes all file descriptors equal to or greater than the given descriptor number. We handle this in two stages. First, we loop and callclose()for any non-rumpclient descriptor value. After we reach the highest rumpclient descriptor we can execute a hostclosefrom()using one greater than the highest rumpclient descriptor as the argument. Finally, we must execute closefrom in the rump kernel, but this time we must avoid closing any dup2'd file descriptors.
Finally, we must deal with asynchronous I/O calls that may have to call both kernels. For example, in networking clients it is common to pass in one descriptor for the tty and one descriptor for the network socket. Since we do not have a priori knowledge of which kernel will have activity first, we must query both. This is done by creating a thread to call the second kernel. Since only one kernel is likely to produce activity, we also add one host kernel pipe and one rump kernel pipe to the file descriptor sets being polled. After the operation returns from one kernel, we write to the pipe of the other kernel to signal the end of the operation, join the thread, collect the results, and return.
Supporting fork()
Recall, the fork() system call creates a copy
of the calling process which essentially differs only by
the process ID number. For us this means that after forking
the child process shares the parent's rumpclient socket.
This must be addressed, since use of the same socket from multiple
independent processes will result in corrupt transmissions.
To fix this, the child process must open a new connection.
However, as stated earlier, a new connection is treated
like an initial login. This means that the child will not
have access to the parent's rump kernel state, including
file descriptors. Applications such as web servers and
shell input redirection depend on the behaviour of file
descriptors being preserved over fork, so we must preserve
that information if we wish to use such applications.
We solve the issue by hijacking the fork call and dividing forking into three phases. First, the forking process informs the rump kernel that it is about to fork. The rump kernel does a fork of the rump process context, generates a cookie and sends that to the client as a response. Next, the client process calls the host's fork routine. The parent returns immediately to the caller. The newly created child establishes its own connection to the rump kernel server. It uses the cookie to perform a handshake where it indicates it wants to attach to the rump kernel process the parent forked off earlier. Only then does the child return to the caller. This way both host and rump process contexts have expected semantics over a host process fork.
In pseudo-code, forking does roughly the following:
pid_t
rumpclient_fork()
{
pid_t rv;
cookie = rumpclient_prefork();
switch ((rv = host_fork())) {
case 0:
rumpclient_fork_init(cookie);
break;
default:
break;
case -1:
error();
}
return rv;
}
Supporting execve()
Another interesting system call is exec. Here the requirements are the "opposite" of fork. Instead of creating a new process, the same rump process context must be preserved over a host's exec call. Since calling exec replaces the memory image of a process with that of a new one from disk, we lose all of the rump client state in memory — recall, though, that exec does not close file descriptors. The important state includes for example dup2 file descriptor alias table, the process's current working directory (used to select host/rump kernels when a non-absolute path is given), and the rumpclient descriptors.
To address the issue, we hijack the
execve
system call. Before calling the host's execve, we first
augment the environment (envp) to contain all
the rump client state. After that, execve()
is called with the augmented environment. When the rump
client constructor runs, it will search the environment
for these special variables. If found, it will initialize
state from them instead of starting from a pristine state.
As with fork, most of the kernel work is done by the host
system. However, there is also some rump kernel state we
must attend to when exec is called. First, the process
command name changes to whichever process was exec'd. This
information is displayed e.g. by rump.sockstat,
so we must make sure we transmit the updated command name
from the client to the rump kernel. Furthermore, although
file descriptors are in general not closed in exec, ones
marked with FD_CLOEXEC should be closed, and
we call the appropriate kernel routine to have them closed.
The semantics of exec also require that only the calling thread is present after exec. While the host takes care of removing all threads from the client process, some of them might have been blocking in the rump kernel and will continue to block until their condition has been satisfied. If they alter the rump kernel state after their blocking completes at an arbitrary time in the future, incorrect operation may result. Therefore, during exec we signal all lwps belonging to the exec'ing process that they should exit immediately. We will complete the exec handshake only after all such lwps have returned from the rump kernel.
Performance
Detailed performance measurements are beyond the scope of this document. However, we discuss performance and provide anecdotal evidence. The question we are looking to answer is if performance is on an acceptable level or if it is necessary to improve it.
A rump system call is more than an order of magnitude slower
than a regular system call. This is mostly because of the
scheduling latency between sending a request and it being
handled by the rump kernel. Typically, the more copyin/out
operations are involved with a system call, the slower the
syscall gets as compared to a host kernel call. The most
efficient optimization would be to decrease the number of remote
copyin/out requests required for completing a syscall request.
This can be done in a fairly straightforward manner by
augmenting the syscall definitions and prearranging parameters
so that pre-known copyin/out I/O can be avoided. Possible
options are piggybacking the data copy as part of syscall
request/response, or using interprocess shared memory (in
case the client and server are on the same machine). For
example, the open() syscall will, barring
an early error, always copy in the pathname string. We can
make the syscall code set things up so that the pathname
copyin is immediately satisfied with a local copy operation instead
of a remote request and the associated roundtrip delay.
For several weeks I have been doing my regular desktop web browsing through a rump networking stack. There is no human-perceivable difference between the performance of a rump networking stack and the host networking stack, either in bulk downloads of speeds up to 10Mbps, flash content or interactive page loads. This suggests that without a more specific use case, any optimizations along the system call path are premature. The only human-perceivable difference is the ability to reboot the TCP/IP stack from under the browser without having to close the browser first.
Conclusions
It is possible to run standard NetBSD kernel components in
userspace as rump kernels. This document presented the
rump sysproxy functionality and the
rumphijack library. The former allows
rump kernel clients to communicate with rump kernel server over
a TCP/IP or local socket and the latter allows to establish
a per-process policy for redirecting system calls from
unmodified binaries to a rump kernel. The implementation
supports all advanced cases necessary for real-world
programs, such as fork(),
execve() and dup2().
This makes it possible for arbitrary applications to act as
clients for NetBSD kernel code running in userspace and
selectively use alternate features in areas such as file systems
and networking.
The motivations for such kernel server setups are many. They range from increased security to using experimental features without compromising the entire system and even to having access to drivers not available for the host kernel version in question. Furthermore, since rump servers are extremely lightweight and do not require baggage such as root file systems, it is possible to virtualize the NetBSD kernel on an unforeseen scale: up to thousands of instances on commodity hardware.
All of the features described in this document have been implemented in production quality code. If you are interested in trying them in reality, please read the related tutorial for instructions and ideas for further use cases.
Acknowledgements
Christoph Badura, Valeriy Ushakov and Thomas Klausner provided insightful questions and suggestions on a draft version of this article.